공유 메모리란?
공유 메모리는 같은 메모리 공간을 2개 이상의 프로세스가 공유하는 것으로, 같은 메모리 공간을 사용하므로 이를 통해 데이터를 주고받을 수 있는 통신 방법이다.
특징
- 고성능: 메모리를 직접 공유하므로 가장 빠른 IPC 방법
- 동기화 필요: 여러 프로세스가 메모리를 공유하므로 메모리를 읽고 쓸 때 자연스럽게 동기화가 요구됨
- 커널 지원: 프로세스 간 메모리 공유는 커널의 도움이 필요
시스템 V의 프로세스 간 통신(IPC)
시스템 V IPC는 메시지 큐, 공유 메모리, 세마포어를 묶어서 부르는 용어다.
IPC 객체 구성
시스템 V IPC를 사용하려면 IPC 객체를 생성해야 한다.
- 키(Key): IPC 객체를 식별하는 고유 번호
- 식별자(Identifier): 현재 사용 중인 IPC의 상태를 확인하고 관리
# 현재 시스템의 IPC 상태 확인
ipcs -m # 공유 메모리 세그먼트 확인
ipcs -q # 메시지 큐 확인
ipcs -s # 세마포어 확인공유 메모리 유형
1. 단일 스레드의 시간차 접근
상황: 하나의 스레드가 서로 다른 시점에 자원에 접근하는 경우
// 예시: 하나의 스레드가 변수 x를 1초 후에 읽고, 2초 후에 다시 읽는 상황
int x = 10;
sleep(1);
printf("첫 번째 읽기: %d\n", x);
sleep(1);
printf("두 번째 읽기: %d\n", x);특징:
- Race condition 문제는 없음
- 외부 입출력 동작이 진행되고 있는 상황(이벤트, I/O)에서는 문제가 될 수 있음
2. 프로세스 내 스레드 간 공유
상황: 하나의 프로세스 내에서 서로 다른 스레드들이 자원에 접근하는 경우
#include <pthread.h>
int shared_variable = 0; // 공유 자원
void* thread_function(void* arg) {
for (int i = 0; i < 1000; i++) {
shared_variable++; // Race condition 발생 가능!
}
return NULL;
}특징:
- 가장 흔한 공유 메모리 형태
- 공유 자원에 동시에 접근 시 race condition 문제 발생
- 뮤텍스, 세마포어 등으로 동기화 필요
3. 프로세스 간 자원 공유
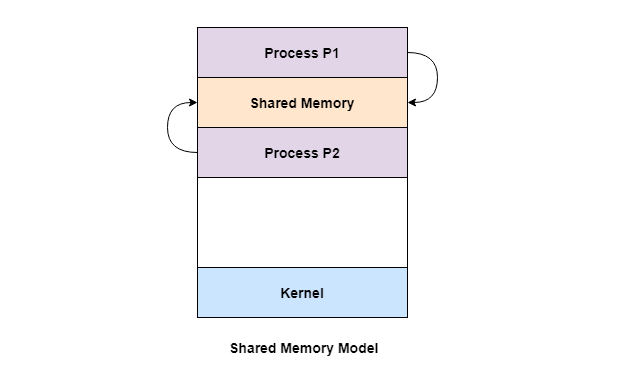
상황: 서로 다른 프로세스들이 자원에 접근하는 경우
// 프로세스 A
void* shared_memory = mmap(...);
strcpy(shared_memory, "Hello from Process A");
// 프로세스 B
void* shared_memory = mmap(...);
printf("Received: %s\n", (char*)shared_memory);특징:
- 가장 복잡한 형태
- 커널의 도움이 반드시 필요
- 강력한 동기화 메커니즘 필요
캐시(Cache) 메모리 계층
캐시는 속도가 빠른 소형 메모리로, 자주 사용하는 데이터를 임시로 저장해 CPU가 빠르게 접근할 수 있도록 돕는다.
메모리 계층 구조
현대 컴퓨터는 여러 레벨의 캐시를 가진다. (멀티 코어는 각 코어마다 자신만의 캐시 계층 구조를 지님)
| 레벨 | 유형 | 크기 | 접근 시간 | 설명 |
|---|---|---|---|---|
| L0 | CPU 레지스터 | ~100 B | ~0 클럭 사이클 | CPU 내부의 가장 빠른 저장공간 |
| L1 | Level 1 캐시 | ~10 KB | ~1-5 클럭 사이클 | CPU와 가까운 1차 캐시 |
| L2 | Level 2 캐시 | ~100 KB | ~10+ 클럭 사이클 | L1보다 크지만 조금 느림 |
| L3 | Level 3 캐시 | ~1 MB | ~30+ 클럭 사이클 | 멀티코어 간 공유 캐시 |
| L4 | 메인 메모리(RAM) | ~10 GB | ~100+ 클럭 사이클 | 캐시에 없는 데이터를 가져옴 |
캐시 동작 원리
- 캐시 미스: 어떤 데이터가 L1에 없으면 L2에서 찾기
- 계층적 검색: L2에도 없으면 L3로, 그래도 없으면 RAM에서 찾아서 캐시에 올림
- 성능 영향: 레벨이 올라갈수록 시간이 기하급수적으로 증가(용량↑, 속도↓)하기 때문에 성능 저하 발생
중요: **캐시 적중률(cache hit rate)**이 성능에 결정적 영향을 미침
Write Propagation Problem (쓰기 전파 문제)
문제 상황
로컬 캐시에 대한 쓰기는 동시적 흐름에 즉시 보이지 않을 수 있다
// CPU Core 1에서 실행되는 스레드 A
int shared_data = 100;
shared_data = 200; // A의 캐시에만 쓰기
// CPU Core 2에서 실행되는 스레드 B
printf("%d\n", shared_data); // 여전히 100을 읽을 수 있음!원인 분석
- 개별 캐시: CPU는 각 코어마다 자기만의 캐시를 가짐
- 지연된 전파: A 스레드가 어떤 값을 자기 캐시에만 수정
- 가시성 문제: B 스레드(다른 코어)는 그 값이 바뀐 것을 모를 수 있음
해결 방법
각자 가지고 있는 캐시 데이터를 RAM으로 밀어올린다 (캐시의 flush)
Memory Barriers (메모리 배리어)
개념
동시적(비동기적)으로 수행되던 메모리 관련 작업을 일시적으로 동기적으로 취급해 쓰기 순서를 보장한다.
즉, 캐시의 flush를 유도함으로써 다른 스레드가 정확한 값을 볼 수 있게 해주면서 쓰기 전파 문제를 해결한다.
하드웨어 메모리 배리어 명령어
x86-64: mfence (memory fence)
mov $200, %eax
mov %eax, shared_data
mfence ; 메모리 배리어ARM: dmb (Data Memory Barrier)
str r0, [r1] ; 메모리에 쓰기
dmb sy ; 데이터 메모리 배리어프로세스 내 vs 프로세스 간 메모리 공유
프로세스 내 메모리 공유
프로세스 내에서는 특별한 설정 없이 메모리가 공유된다
#include <pthread.h>
int global_var = 0; // 모든 스레드가 공유
void* thread_func(void* arg) {
global_var++; // 특별한 설정 없이 접근 가능
return NULL;
}
int main() {
pthread_t threads[2];
pthread_create(&threads[0], NULL, thread_func, NULL);
pthread_create(&threads[1], NULL, thread_func, NULL);
// ...
}프로세스 간 메모리 공유
프로세스 간 메모리 공유는 커널의 도움이 필요하며, 다음 방법들이 있다.
fork()전에 공유 매핑 생성shm_open()으로 이름이 있는 매핑에 연결- 메모리 매핑된 파일에 연결
mmap() 시스템 콜
함수 시그니처
#include <sys/mman.h>
void* mmap(void* addr, size_t len, int prot, int flags, int fd, off_t offset);매개변수 설명
- addr: 매핑을 원하는 주소 (보통 NULL로 시스템이 결정하게 함)
- len: 매핑할 크기
- prot: 보호 모드 (
PROT_READ,PROT_WRITE,PROT_EXEC) - flags: 매핑 플래그 (
MAP_SHARED,MAP_PRIVATE,MAP_ANONYMOUS) - fd: 파일 디스크립터
- offset: 파일 내 오프셋
기본 사용 예제
#include <sys/mman.h>
#include <fcntl.h>
int main() {
// 익명 메모리 매핑 (파일 없이)
void* memory = mmap(NULL, 4096,
PROT_READ | PROT_WRITE,
MAP_ANONYMOUS | MAP_PRIVATE,
-1, 0);
if (memory == MAP_FAILED) {
perror("mmap failed");
return 1;
}
// 메모리 사용
strcpy(memory, "Hello, mmap!");
printf("%s\n", (char*)memory);
// 해제
munmap(memory, 4096);
return 0;
}shm_open() 시스템 콜
함수 시그니처
#include <sys/mman.h>
#include <fcntl.h>
int shm_open(const char *name, int flags, int mode);특징
- flags와 mode 인자:
open()과 동일한 방식으로 사용 - 커널 메모리 버퍼: 참조하는 파일 디스크립터 생성
- mmap()과 연동: 반환된 파일 디스크립터는
mmap()과 함께 사용 가능
예제
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>
int main() {
// 1. 공유 메모리 객체 생성
int fd = shm_open("/shm_example", O_CREAT | O_RDWR, 0600);
if (fd == -1) {
perror("shm_open failed");
return 1;
}
// 2. 매핑 크기 설정
if (ftruncate(fd, 4096) == -1) {
perror("ftruncate failed");
return 1;
}
// 3. 메모리 매핑
void* mapping = mmap(NULL, 4096,
PROT_READ | PROT_WRITE,
MAP_SHARED, fd, 0);
if (mapping == MAP_FAILED) {
perror("mmap failed");
return 1;
}
// 4. 공유 메모리 사용
strcpy(mapping, "Hello from shared memory!");
printf("Written: %s\n", (char*)mapping);
// 5. 정리
munmap(mapping, 4096);
close(fd);
shm_unlink("/shm_example"); // 공유 메모리 객체 삭제
return 0;
}프로세스 간 공유 예제
프로세스 A (Writer):
#include <sys/mman.h>
#include <fcntl.h>
#include <string.h>
int main() {
int fd = shm_open("/communication", O_CREAT | O_RDWR, 0600);
ftruncate(fd, 4096);
char* shared_memory = mmap(NULL, 4096,
PROT_READ | PROT_WRITE,
MAP_SHARED, fd, 0);
strcpy(shared_memory, "Message from Process A");
printf("Process A: Message written\n");
sleep(10); // 다른 프로세스가 읽을 시간 제공
munmap(shared_memory, 4096);
close(fd);
return 0;
}프로세스 B (Reader):
#include <sys/mman.h>
#include <fcntl.h>
int main() {
int fd = shm_open("/communication", O_RDWR, 0);
char* shared_memory = mmap(NULL, 4096,
PROT_READ | PROT_WRITE,
MAP_SHARED, fd, 0);
printf("Process B received: %s\n", shared_memory);
munmap(shared_memory, 4096);
close(fd);
shm_unlink("/communication"); // 정리
return 0;
}실행 파일 로딩에서의 mmap() 활용
실행 파일도 mmap()을 사용하여 메모리에 로드된다.
ELF 섹션별 매핑 전략
.text 섹션: PROT_READ | PROT_EXEC
- 실행 가능한 코드
- 읽기와 실행만 허용
.rodata 섹션: PROT_READ
- 읽기 전용 데이터 (문자열 상수 등)
- 읽기만 허용
.data 섹션: PROT_READ | PROT_WRITE
- 초기화된 전역 변수
- 읽기와 쓰기 허용
텍스트와 읽기 전용 데이터: MAP_SHARED로 RAM 절약
- 여러 프로세스가 같은 실행 파일을 실행할 때 메모리 공유
BSS: MAP_ANONYMOUS와 PROT_READ | PROT_WRITE 사용
- 초기화되지 않은 전역 변수
- 파일 백업 없이 0으로 초기화된 메모리
실행 파일 로딩 시뮬레이션
// 간단한 ELF 로더 시뮬레이션
void load_elf_sections(int fd) {
// .text 섹션 로딩
void* text_segment = mmap((void*)0x400000, text_size,
PROT_READ | PROT_EXEC,
MAP_SHARED | MAP_FIXED,
fd, text_offset);
// .data 섹션 로딩
void* data_segment = mmap((void*)0x600000, data_size,
PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_FIXED,
fd, data_offset);
// .bss 섹션 생성
void* bss_segment = mmap((void*)0x700000, bss_size,
PROT_READ | PROT_WRITE,
MAP_ANONYMOUS | MAP_PRIVATE | MAP_FIXED,
-1, 0);
}공유 메모리 동기화
문제점
공유 메모리는 빠르지만 동기화 문제를 해결해야 한다.
// 위험한 코드 - Race Condition 발생 가능
int* shared_counter = /* 공유 메모리 */;
void increment() {
(*shared_counter)++; // 원자적이지 않음!
}해결 방법들
1. 원자적 연산 사용
#include <stdatomic.h>
atomic_int* shared_counter = /* 공유 메모리 */;
void safe_increment() {
atomic_fetch_add(shared_counter, 1);
}2. 세마포어 사용
#include <semaphore.h>
sem_t* mutex = /* 공유 메모리 내 세마포어 */;
void protected_increment() {
sem_wait(mutex);
(*shared_counter)++;
sem_post(mutex);
}3. 메모리 배리어 명시적 사용
void careful_write() {
*shared_data = new_value;
__sync_synchronize(); // GCC 메모리 배리어
}성능 최적화 팁
1. 메모리 지역성 활용
// 좋은 예: 순차적 접근
for (int i = 0; i < size; i++) {
shared_array[i] = i; // 캐시 친화적
}
// 나쁜 예: 무작위 접근
for (int i = 0; i < size; i++) {
shared_array[random() % size] = i; // 캐시 미스 빈발
}2. False Sharing 방지
// 문제 상황: False Sharing
struct {
int counter1; // CPU 코어 1이 사용
int counter2; // CPU 코어 2가 사용 - 같은 캐시 라인!
} shared_data;
// 해결책: 패딩 추가
struct {
int counter1;
char padding[60]; // 캐시 라인 크기만큼 패딩
int counter2;
} optimized_data;3. 적절한 mmap 플래그 선택
// 읽기 전용 공유 데이터
void* readonly_shared = mmap(NULL, size,
PROT_READ,
MAP_SHARED, // 메모리 절약
fd, 0);
// 프로세스별 쓰기 가능 데이터
void* private_copy = mmap(NULL, size,
PROT_READ | PROT_WRITE,
MAP_PRIVATE, // COW 활용
fd, 0);디버깅과 모니터링
공유 메모리 상태 확인
# 현재 공유 메모리 상태
ipcs -m
# 특정 프로세스의 메모리 맵
cat /proc/[PID]/maps
# 메모리 사용량 모니터링
watch -n 1 'cat /proc/meminfo | grep -E "(Shared|Mapped)"'일반적인 문제와 해결책
1. 메모리 누수
// 문제: munmap 호출 안 함
void* memory = mmap(...);
// munmap 없이 종료
// 해결: 적절한 정리
void cleanup() {
if (memory != MAP_FAILED) {
munmap(memory, size);
memory = MAP_FAILED;
}
}2. 권한 문제
// 문제: 잘못된 권한 설정
int fd = shm_open("/test", O_CREAT | O_RDWR, 0000); // 권한 없음
// 해결: 적절한 권한 설정
int fd = shm_open("/test", O_CREAT | O_RDWR, 0600); // 소유자만 읽기/쓰기마치며
공유 메모리는 프로세스 간 통신에서 가장 빠른 방법이지만, 그만큼 복잡한 동기화 문제를 수반한다.
- 성능 vs 복잡성: 가장 빠르지만 동기화가 복잡
- 캐시 일관성: Write Propagation 문제와 메모리 배리어의 중요성
- 시스템 콜 활용:
mmap()과shm_open()의 적절한 사용 - 메모리 계층: 캐시 구조 이해를 통한 성능 최적화